User talk:Kutchkutch
Welcome!
Hello, welcome to Wiktionary, and thank you for your contribution so far. Here are a few good links for newcomers:
- How to edit a page is a concise list of technical guidelines to the wiki format we use here: how to, for example, make text boldfaced or create hyperlinks. Feel free to practice in the sandbox. If you would like a slower introduction we have a short tutorial.
- Entry layout explained (ELE) is a detailed policy documenting how Wiktionary pages should be formatted. All entries should conform to this standard, the easiest way to do this is to copy exactly an existing page for a similar word.
- Our Criteria for inclusion (CFI) define exactly which words Wiktionary is interested in including. There is also a list of things that Wiktionary is not for a higher level overview.
- The FAQ aims to answer most of your remaining questions, and there are several help pages that you can browse for more information.
- We have discussion rooms in which you can ask any question about Wiktionary or its entries, a glossary of our technical jargon, and some hints for dealing with the more common communication issues.
I hope you enjoy editing here and being a Wiktionarian! If you have any questions, bring them to the Wiktionary:Information desk, or ask me on my talk page. If you do so, please sign your posts with four tildes: ~~~~ which automatically produces your username and the current date and time.
Again, welcome! --Ivan Štambuk 06:42, 3 January 2010 (UTC)
Marathi[edit]
Marathi does not use the Latin script. Mglovesfun (talk) 22:06, 10 January 2010 (UTC)
- Where possible, foreign entries should have an English translation (e.g. bhaji) rather than a definition. SemperBlotto 22:51, 10 January 2010 (UTC)
Hindi words[edit]
None of your recent entries have ==language== sections. They may get deleted. SemperBlotto 08:09, 30 January 2010 (UTC)
Thanks for all the changes! —Aryaman (मुझसे बात करो) 10:29, 6 September 2017 (UTC)
- Thanks for noticing! I was curious how you were able to obtain the Maharashtri Prakrit word when you first made this page and Prakrit words on other pages such as those in this category [1] and especially in the Brahmi script. Did you find them in old Prakrit books on archive.org or Google Books such as [2] [3] and transliterate them into Brahmi from Latin script? Doing so appears to be hard since the books are so old and sometimes hard to understand. It is much easier to use digitised and searchable dictionaries from [4] but it does not seem to have any Prakrit resources. It does have an Old Marathi dictionary though. Kutchkutch (talk) 19:14, 6 September 2017 (UTC)
- That website does have Prakrit in Turner's dictionary: [5]. It says:
- Pk. makkaḍa -- m., °ḍī f., maṁkaḍa -- , °kaṇa -- m.
- I think Turner only gives Maharashtri Prakrit. Some other sources: [6], [7] which give other Prakrit lects. For typing in Prakrit I use Module:typing-aids, so
{{subst:chars|m|psu|makkaDa}}gives Lua error in Module:parameters at line 95: Parameter 1 should be a valid language or etymology language code; the value "psu" is not valid. See WT:LOL and WT:LOL/E.. [8], [9] have some pre-transliterated Prakrit texts too. Great to have another Indian-language editor! User:माधवपंडित is another one, he speaks Konkani, Kannada, and Hindi (and apparently some Marathi). —Aryaman (मुझसे बात करो) 19:33, 6 September 2017 (UTC)- Thanks for discussing this! It seems that ‘Prakrit’ on its own is not a single language, and the word ‘Prakrit’ collectively refers to Middle Indic languages. If a source (Turner in this case) mentions a word in Prakrit without specifying the lect (Ardhamāgadhī, Mahārāṣṭrī, Śaurasenī, etc), would it be fair to say that the word exists in all lects with identical forms each worthy of its own Wiktionary entry? Or would more research or judgement be necessary to say which lects have the word and in what form as you did when you said ‘I think Turner only gives Maharashtri Prakrit [in this case]’? And in this case it appears Turner gives a feminine version of the first word with the ending °ḍī f. and two additional masculine words maṁkaḍa -- , °kaṇa -- m. Would all of these words be worthy of their own Wiktionary entries?
- That website does have Prakrit in Turner's dictionary: [5]. It says:
- With regard to script, there appears to be a convention for which script to be used for each language on Wiktionary. For example, the consensus in a section on your talk page [10] is that Prakrit lects should be in the Brahmi script and Pali should be in the Latin script with the Template:pi-alt being a nice way to show the alternate scripts. According to Wikipedia, Konkani can be written in various scripts and it appears all Konkani lemmas on Wiktionary are in the Devanagari script. Marathi used to be written in the Mōḍī script and Mōḍī script is now in Unicode so should Old Marathi lemmas on Wiktionary be in the Modi script? Or not since there are few Modi Unicode fonts?
- Is there no such thing as a Mahārāṣṭrī Apabhraṃśa (or Ardhamāgadhī Apabhraṃśa) just like Gurjar Apabhramsa (Category:Gurjar_Apabhramsa_language) and Sauraseni Apabhramsa (Category:Sauraseni_Apabhramsa_language)? Kutchkutch (talk) 00:05, 7 September 2017 (UTC)
- @Kutchkutch: The consensus here is to treat Prakrit as a class of middle Middle-Indo-Aryan languages (the old MIA languages are Pali, the younger MIA languages are Apabhramsas). So there is a CAT:Sauraseni Prakrit language, CAT:Ardhamagadhi Prakrit language, etc. I have suggested merging them because of how regular they are in spelling differences, and the fact that they were pretty much mutually intelligible (many medieval Indian plays used different Prakrit lects for different characters), but User:DerekWinters disagreed (he too knows quite a bit about Prakrit).
- Is there no such thing as a Mahārāṣṭrī Apabhraṃśa (or Ardhamāgadhī Apabhraṃśa) just like Gurjar Apabhramsa (Category:Gurjar_Apabhramsa_language) and Sauraseni Apabhramsa (Category:Sauraseni_Apabhramsa_language)? Kutchkutch (talk) 00:05, 7 September 2017 (UTC)
- By Turner using Maharashtri Prakrit, I mean he usually gives the standard Maharashtri Prakrit spelling, e.g. I've noticed for verbs he always drops consonants in the ending, e.g for भवति "to become" he gives Prakrit bhavaï, where the spelling for Sauraseni is bhodi.
- All those words do merit an entry as alternative spellings if they pass WT:CFI, basically there should be at least 3 durable citations (if it's obvious that a word is citable, you don't actually need to provide the citations).
- Old Marathi could be given in the Modi script, but since there is such patchy Unicode support idk if that would be a good idea. Same for Prakrit, I'd rather have it use the Latin script (like Pali) or Devanagari so people can actually search for the entries. But, our support for Prakrit in etymologies is already pretty good with Brahmi. Finally, I'm not sure about Apabhramsa for Marathi, but since Old Marathi is like early 1000's to 1400ish, and Prakrit is like 100 BC to 500 CE, perhaps there is a Marathi Apabhramsa. —Aryaman (मुझसे बात करो) 00:40, 7 September 2017 (UTC)
कसे आहात? इकडे मराठी बोलणारांची उणीव आहे। भेटून आनंद झाला। -- mādhavpaṇḍit (talk) 07:01, 7 September 2017 (UTC)
- धन्यवाद! उणीव खरंच आहे। मला पण भेटून आनंद झाला। Kutchkutch (talk) 21:38, 7 September 2017 (UTC)
^मैं यह बिल्कुल नहीं समझा... मैंने एक मराठी शब्दावली ढूंढ डाली है, [11], क्या आप इन मूलभूत शब्द को add कर सकते हैं? धन्यबाद —Aryaman (मुझसे बात करो) 01:00, 13 September 2017 (UTC)
- इस निवेदन के लिए बहुत धन्यवाद! अब तक मैंने इतना बड़ा काम नहीं किया और थोड़ा समय लगेगा लेकिन कोशिश तो ज़रूर करूंगा!
- Even though I’ve been learning Hindi for many many years and perfectly understood what you’ve written, I don’t consider myself completely fluent in it yet but it’s probably good enough for English Wiktionary but maybe not for Hindi Wikipedia [12] :-)
- I’ve noticed (as you must have too) that some of the words on that list are English words transliterated/borrowed into Devanagari/Marathi. Furthermore, some of those words must already have entries as Hindi and other languages even if the Marathi entry may not exist yet. Kutchkutch (talk) 08:46, 13 September 2017 (UTC)
- हिंदी विकिपीडिया पर सिर्फ़ शुद्ध हिंदी का इस्तेमाल करते हैं, जो वैसे बहुत कम सुनी जाती है। मैं भी वहां उतना edit नहीं करता… मुझे हिंदी आती है, संस्कृत नहीं! English borrowings are fair game still, see CAT:Hindi terms borrowed from English (but they can wait for now, since they're very simple to translate). We're in serious need of Marathi lemmas, thank you so much for your contributions! —Aryaman (मुझसे बात करो) 10:23, 13 September 2017 (UTC)
Babel[edit]
You should add {{Babel}} to your userpage btw, maybe {{Babel|mr|en-4|hi-4}}?
—Aryaman (मुझसे बात करो) 01:07, 20 September 2017 (UTC)
- Also, I found another great resource : [13], It has 27,000 Marathi example sentences! —Aryaman (मुझसे बात करो) 01:18, 20 September 2017 (UTC)
- Thanks for the suggestion and the link! Kutchkutch (talk) 01:23, 20 September 2017 (UTC)
- @AryamanA Do you know if the example sentences at [14] and Tatoeba can be used in their entirety or in a modified way without mentioning the source? Some example sentences have audio files and the author for the Marathi audio files has stated that Tatoeba needs to be attributed if the audio files are used, but there is perhaps no need to mention the source if only the text is used with some possible modifications. Kutchkutch (talk) 03:21, 1 December 2017 (UTC)
- Their licence requires attribution to be provided. —AryamanA (मुझसे बात करें • योगदान) 11:40, 1 December 2017 (UTC)
- @AryamanA: Ok thanks for answering! I was just looking for a place to look for inspiration, if it's too complicated to properly attribute Tatoeba perhaps it shouldn't be used yet. Creativity is not as easy as I thought. Sometimes I write a usage example and then think it's not very effective in showing the word's meaning.
- Also, when should
{{uxi}}be used instead of{{ux}}? Should it be used when a usage example is too short to occupy several lines? I was also wondering why{{hi-usex}}is is used for Hindi instead of the default{{ux}}or{{uxi}}. Is{{hi-usex}}customised in some way or is it simply a shortcut for{{ux|hi|यह एक उदाहरण है।}}? Kutchkutch (talk) 22:03, 1 December 2017 (UTC)- @Kutchkutch: Right now, it automatically makes it inline (
{{uxi}}) for short examples, and it highlights the word to make it more visible. Otherwise, it is pretty much the same as{{ux}}/{{uxi}}. And yes,{{uxi}}is for short phrases or sentences usually, but I've noticed some languages like Greek only use{{uxi}}, for stylistic reasons. —AryamanA (मुझसे बात करें • योगदान) 22:49, 1 December 2017 (UTC)
- @Kutchkutch: Right now, it automatically makes it inline (
- Their licence requires attribution to be provided. —AryamanA (मुझसे बात करें • योगदान) 11:40, 1 December 2017 (UTC)
Hello..[edit]
Hello.. Happy to see fellow Indian on Wiktionay. Just curiously land here knowing that Kutch is a region in Gujarat state of India. So I found your name interesting. Regards,--Nizil Shah (talk) 06:54, 4 October 2017 (UTC)
- @Nizil Shah Thanks for saying hello and it's nice to meet you! You are correct about my username; it does refer to the Kutch region of Gujarat. Using this region for my username was a random choice. Unfortunately, I do not know much about Kutch or its language other than what can be found at Wikipedia. I see on your talk page that you have posted some links about the Kutchi language in a discussion with User:DerekWinters.
- I can see that User:DerekWinters and you are both Gujarati-language editors. I have not had the chance to interact with User:DerekWinters yet.
- I have a Gujarati-related question that I wanted to ask you (or User:DerekWinters if I ever get the chance to interact with him). I wanted to add 'અમદાવાદ, વડોદરા, સુરત, રાજકોટ અને મુંબઈથી પ્રગટ થતું દૈનિક.' as a usage example for the entry અને. I was unsure what the words 'પ્રગટ' and 'થતું' mean so I decided to remove the usage example. Is the correct translation of that Gujarati phrase 'Presented daily from Ahmedabad, Vadodara, Surat, Rajkot and Mumbai'? If you can confirm this translation I might consider re-adding this usage example to the the entry અને. Kutchkutch (talk) 01:25, 5 October 2017 (UTC)
- 'પ્રગટ થતું' mean 'published' here. That translation was incorrect. The correct translation: 'A daily published from Ahmedabad, Vadodara, Surat, Rajkot and Mumbai'. Such tag is used on the top of newspapers/dailies. Feel free to ask whenever you have any question regarding Gujarati. I am native Gujarati speaker.
- Kutch is a wonderful place to live or visit, I can say. I can understand Kutchi partially but could not read it if written in Sindhi script. Regards,--Nizil Shah (talk) 11:46, 5 October 2017 (UTC)
- @Nizil Shah:Thanks! As you pointed out, I saw that phrase on the top of the front pages of Gujarati newspapers.
- All the Kutchi words in Category:Kachchi lemmas appear to be in the Gujarati script so far. Although the Sindhi Perso-Arabic script has similarities with the Urdu script, it appears to have a letter corresponding to almost every Devanagari letter, which Urdu does not have. Wikipedia's language family tree suggests that Kutchi is closer to Sindhi than Gujarati, but below it says 'Kutchi is often thought to be a mixture of Sindhi, Gujarati, and Rajasthani'. Kutchkutch (talk) 05:09, 6 October 2017 (UTC)
- @Kutchkutch:, Kutch has been part of Gujarat since its foundation in 1960. Gujarati is a primary language taught across all schools in Gujarat (except large number of English Medium schools where it is taught as a secondary language). As far as I know, no school in Kutch teach Kutchi language. Kutchi is written in Sindhi and Gujarati scripts as it has not single standard Kutchi script. As there is not much support for Sindhi script, most writers prefers Gujarati script. You are right that Sindhi script has corresponding letter for Devnagari script. It is somewhat similar to the case of Western and Eastern Punjabi: similar language but different scripts due to international borders. Kutchi origin people living is Pakistan uses Sindhi script while living Kutchi people in Kutch, Gujarat, India uses Gujarati script. Same applies to Sindhi language too: Sindhi living in India uses Devnagari/Gujarati script while Sindhis living in Pakistan uses Sindhi script. Sorry for very late reply. I had missed this conversation. @DerekWinters, pinging you for inputs on "technical" linguistic knowledge which I have none.--Nizil Shah (talk) 06:15, 8 January 2018 (UTC)
love button[edit]
Hello. I'm amazed that there are so many words for "clitoris" in Marathi (see the translation table there). Do you vouch for all of them? And would you mind creating the most common? Thank you! --Barytonesis (talk) 20:25, 12 November 2017 (UTC)
- @Barytonesis: Yes, it is a bit unusual that there's so many words listed there! I think what happened was there was a user on Marathi Wikipedia that made a glossary of English to Marathi terms related to female anatomy [15] and transferred those translations to Wiktionary. The reason for making such a list might be because since it's a taboo topic many resources such as dictionaries don't even mention them. (In that discussion, one user even suggested it's not suitable to include such topics on Marathi Wikipedia). Those words look like real words. Most of those words could be Sanskrit borrowings and compounds, and since they're not in dictionaries it could be hard to find information about them. Kutchkutch (talk) 22:12, 12 November 2017 (UTC)
Dardic[edit]
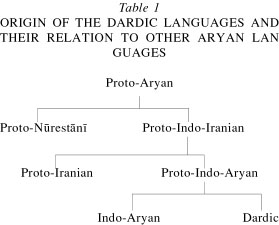
Hey Kutchkutch, I just wanted to mention that Dardic is a descendant of Proto-Indo-Aryan, not Sanskrit. Also, when you add {{desc|inc-dar-pro}}, please don't null it out with |2=-, so we can see which entries need reconstructions. Thank and keep up the good work! --Victar (talk) 05:10, 14 January 2018 (UTC)
- @Victar: I remember reading in some paper that scholars do not consider that all "Dardic" languages to have descended from a single, "Proto-Dardic" language. This is why in spite of so many scholarly articles on Dardic languages, a Proto-Dardic language has not been reconstructed. These "Dardic" languages are instead clusters of groups of languages with similarities existing within the groups and not Dardic as a whole. So Kalasha and Khowar are from one group whereas Torwali and Shina are from the other. This is why I used to earlier null out the Proto Dardic level while listing the descendants and now I don't list it at all. In Kalasha there are some words that originate from Classical Sanskrit times. And nowhere in Kalasha has a linguistic feature been found which was lost in Sanskrit and is reminiscent of Proto-Indo-Aryan. Lastly, I have not seen Kutchkutch dabble in Dardic -- what's this about? -- माधवपंडित (talk) 08:35, 14 January 2018 (UTC)
- @माधवपंडित: This probably isn't the right place for a whole conversation on the legitimacy of Proto-Dardic, but regardless of whether some entries are borrowed, influenced by, or straight-out descended from Sanskrit, I think we can both agree (along with publications on the subject) that Proto-Dardic does not belong below Sanskrit. I brought this up with Kutchkutch because he was adding
{{desc|inc-dar-pro}}below{{desc|sa}}in trees. --Victar (talk) 14:47, 14 January 2018 (UTC)- @Victar: I though Proto-Dardic was a descendant of Vedic Sanskrit... —AryamanA (मुझसे बात करें • योगदान) 16:39, 14 January 2018 (UTC)
- Nope. Some even think it might have been more closely related to Nuristani, but that's probably just due to areal influence. See
{{R:iir-nur:Blažek:2010}}. --Victar (talk) 16:52, 14 January 2018 (UTC)- @Victar: There is something seriously wrong with their divergence dates within Indo-Aryan. They claim Hindi and Punjabi diverged in 1650 CE, but Old Punjabi and Old Hindi had distinct literary traditions by 1300 CE. Their divergence date for Sinhala is 650 BCE (!!) is even before the existence of Pali and the dramatic Prakrits, obviously incorrect; Old Sinhala began in 200 CE. They classify Nepali, Marathi, Gujarati, and Sindhi in a single subfamily ("Northwest Indo-Aryan")... that's so clearly wrong. I'll read the rest, but I have serious doubts about the paper. —AryamanA (मुझसे बात करें • योगदान) 02:36, 15 January 2018 (UTC)
- @AryamanA: I don't want to get into a whole discussion on this user talk page, but the paper gives the placement of Dardic is other publications as well (which I why I referenced it specifically), all not below Sanskrit. Here is a chart from Encyclopædia Iranica, so it's a pretty mainstream opinion. --Victar (talk) 02:46, 15 January 2018 (UTC)
- @Victar: There is something seriously wrong with their divergence dates within Indo-Aryan. They claim Hindi and Punjabi diverged in 1650 CE, but Old Punjabi and Old Hindi had distinct literary traditions by 1300 CE. Their divergence date for Sinhala is 650 BCE (!!) is even before the existence of Pali and the dramatic Prakrits, obviously incorrect; Old Sinhala began in 200 CE. They classify Nepali, Marathi, Gujarati, and Sindhi in a single subfamily ("Northwest Indo-Aryan")... that's so clearly wrong. I'll read the rest, but I have serious doubts about the paper. —AryamanA (मुझसे बात करें • योगदान) 02:36, 15 January 2018 (UTC)
- Nope. Some even think it might have been more closely related to Nuristani, but that's probably just due to areal influence. See
- @Victar: I though Proto-Dardic was a descendant of Vedic Sanskrit... —AryamanA (मुझसे बात करें • योगदान) 16:39, 14 January 2018 (UTC)
- @माधवपंडित: This probably isn't the right place for a whole conversation on the legitimacy of Proto-Dardic, but regardless of whether some entries are borrowed, influenced by, or straight-out descended from Sanskrit, I think we can both agree (along with publications on the subject) that Proto-Dardic does not belong below Sanskrit. I brought this up with Kutchkutch because he was adding
{kind=link}
@Victar: As @माधवपंडित: mentioned, I don't recall any recent dabbling in Dardic (maybe it was a while ago?), but thanks for all the suggestions and the information. I'll keep it in mind if I dabble in Dardic. Kutchkutch (talk) 05:32, 15 January 2018 (UTC)
Are म्हणून (mhaṇūn) and म्हणजे (mhaṇje) the same? —AryamanA (मुझसे बात करें • योगदान) 22:15, 28 March 2018 (UTC)
- @AryamanA: They could be similar in certain cases since they're both derived from the same verb, but they are not the same. म्हणून (mhaṇūn) can be synchronically analysed as म्हणणे (mhaṇṇe) + the completive aspect ऊन (compare conjunctive Hindi कहकर/कहके (kahkar/kahke)). म्हणजे (mhaṇje) is an archaic passive inflection (Old Marathi म्हणिजे (mhaṇije)). From those literal meanings they acquired figurative meanings such as:
- Causal म्हणून: [clause X] म्हणून [clause Y]
- [clause X] → [clause Y]
- Dhongde & Wali conjunction example: [माझ्याकडे पैसे नव्हते] म्हणून [मी चालत आलो].
- [mājhyākḍe paise navhate] mhaṇūn [mī cālat ālo].
- [I had no money] so [I came walking].
- Emphatic negation म्हणून: "Preceded by an interrogative pronoun it expresses a strong negation"
- Dhongde & Wali example: मी काय म्हणून जाईन ― mī kāy mhaṇūn j̈āīn ― I am not going to go at all. (literally, “Why should I go?”)
- Named/Called म्हणून: Preceded by a noun
- इसाक म्हणून आब्राहमाचा पुत्र होता.
- isāk mhaṇūn ābrāhmāċā putra hotā.
- There was a son of Abraham named/called Isaac.
- Equality म्हणजे: X म्हणजे Y
- X = Y [जल] म्हणजे [पाणी]. ― [jal] mhaṇje [pāṇī]. ― [जल] means [पाणी].
- Conditional म्हणजे: [clause X] म्हणजे [clause Y]
- [clause X] → [clause Y]
- [तुम्ही बोलला] म्हणजे [माझं कार्य होईल].
- [tumhī bollā] mhaṇje [mājha kārya hoīl].
- [Should you speak], then indeed [my work will be done].
- Causal म्हणून: [clause X] म्हणून [clause Y]
- Causal म्हणून and Conditional म्हणजे appear to be similar. However, [clause X] in Conditional म्हणजे assumes a fact whereas [clause X] in Causal म्हणून states a fact. Kutchkutch (talk) 05:31, 29 March 2018 (UTC)
- @Kutchkutch: Thank you so much! I've started using this Hindi-Marathi textbook to learn a bit more now. —AryamanA (मुझसे बात करें • योगदान) 15:04, 29 March 2018 (UTC)
- @AryamanA: Ideally this information would be in the entries in the usual entry layout and with any Dhongde & Wali "copyrighted" material rewritten.
- I've already discovered [16], and it's been useful. Perhaps [17] is comparable to this list. Since there's so few Oriya lemmas perhaps [18] could be useful for creating a few. Kutchkutch (talk) 08:13, 30 March 2018 (UTC)
- @Kutchkutch: Thank you so much! I've started using this Hindi-Marathi textbook to learn a bit more now. —AryamanA (मुझसे बात करें • योगदान) 15:04, 29 March 2018 (UTC)
[edit]
Hello! The Wikimedia Foundation is asking for your feedback in a survey. We want to know how well we are supporting your work on and off wiki, and how we can change or improve things in the future. The opinions you share will directly affect the current and future work of the Wikimedia Foundation. You have been randomly selected to take this survey as we would like to hear from your Wikimedia community. The survey is available in various languages and will take between 20 and 40 minutes.
You can find more information about this survey on the project page and see how your feedback helps the Wikimedia Foundation support editors like you. This survey is hosted by a third-party service and governed by this privacy statement (in English). Please visit our frequently asked questions page to find more information about this survey. If you need additional help, or if you wish to opt-out of future communications about this survey, send an email through the EmailUser feature to WMF Surveys to remove you from the list.
Thank you!
[edit]
Every response for this survey can help the Wikimedia Foundation improve your experience on the Wikimedia projects. So far, we have heard from just 29% of Wikimedia contributors. The survey is available in various languages and will take between 20 and 40 minutes to be completed. Take the survey now.
If you have already taken the survey, we are sorry you've received this reminder. We have design the survey to make it impossible to identify which users have taken the survey, so we have to send reminders to everyone. If you wish to opt-out of the next reminder or any other survey, send an email through EmailUser feature to WMF Surveys. You can also send any questions you have to this user email. Learn more about this survey on the project page. This survey is hosted by a third-party service and governed by this Wikimedia Foundation privacy statement. Thanks!
Your feedback matters: Final reminder to take the global Wikimedia survey[edit]
Hello! This is a final reminder that the Wikimedia Foundation survey will close on 23 April, 2018 (07:00 UTC). The survey is available in various languages and will take between 20 and 40 minutes. Take the survey now.
If you already took the survey - thank you! We will not bother you again. We have designed the survey to make it impossible to identify which users have taken the survey, so we have to send reminders to everyone. To opt-out of future surveys, send an email through EmailUser feature to WMF Surveys. You can also send any questions you have to this user email. Learn more about this survey on the project page. This survey is hosted by a third-party service and governed by this Wikimedia Foundation privacy statement.
Community Insights Survey[edit]
Share your experience in this survey
Hi Kutchkutch,
The Wikimedia Foundation is asking for your feedback in a survey about your experience with Wiktionary and Wikimedia. The purpose of this survey is to learn how well the Foundation is supporting your work on wiki and how we can change or improve things in the future. The opinions you share will directly affect the current and future work of the Wikimedia Foundation.
Please take 15 to 25 minutes to give your feedback through this survey. It is available in various languages.
This survey is hosted by a third-party and governed by this privacy statement (in English).
Find more information about this project. Email us if you have any questions, or if you don't want to receive future messages about taking this survey.
Sincerely,
RMaung (WMF) 14:34, 9 September 2019 (UTC)
Reminder: Community Insights Survey[edit]
Share your experience in this survey
Hi Kutchkutch,
A couple of weeks ago, we invited you to take the Community Insights Survey. It is the Wikimedia Foundation’s annual survey of our global communities. We want to learn how well we support your work on wiki. We are 10% towards our goal for participation. If you have not already taken the survey, you can help us reach our goal! Your voice matters to us.
Please take 15 to 25 minutes to give your feedback through this survey. It is available in various languages.
This survey is hosted by a third-party and governed by this privacy statement (in English).
Find more information about this project. Email us if you have any questions, or if you don't want to receive future messages about taking this survey.
Sincerely,
RMaung (WMF) 19:14, 20 September 2019 (UTC)
Reminder: Community Insights Survey[edit]
Share your experience in this survey
Hi Kutchkutch,
There are only a few weeks left to take the Community Insights Survey! We are 30% towards our goal for participation. If you have not already taken the survey, you can help us reach our goal! With this poll, the Wikimedia Foundation gathers feedback on how well we support your work on wiki. It only takes 15-25 minutes to complete, and it has a direct impact on the support we provide.
Please take 15 to 25 minutes to give your feedback through this survey. It is available in various languages.
This survey is hosted by a third-party and governed by this privacy statement (in English).
Find more information about this project. Email us if you have any questions, or if you don't want to receive future messages about taking this survey.
Sincerely,
RMaung (WMF) 17:04, 4 October 2019 (UTC)
Acknowledging my (multiple) errors[edit]
Thanks for fixing the pronunciation at the Konkani entries! I don't know what I was thinking when I mistakenly entered kn-IPA in place of kok-IPA. And then the mistake was carried forward when I used copy-paste for other Konkani entries. Thanks again and sorry for the trouble. -- Bhagadatta (talk) 03:17, 5 October 2020 (UTC)
- @Bhagadatta: Even I make such errors, and many of them are later corrected by you. Copy-pasting without a detailed scrutiny is probably why they happen. In this case, there were a few Konkani terms in CAT:Kannada terms with IPA pronunciation.
- Since there's no senses related to cooking at RC:Proto-Indo-European/lendʰ-, should
|id=to cookbe added to{{PIE root|kok|lendʰ}}at रांद्चे (rāndce) and the other cognates? Kutchkutch (talk) 08:15, 5 October 2020 (UTC)- Oh yes, it's always better to do that with homonymous roots in PIE. -- Bhagadatta (talk) 09:30, 5 October 2020 (UTC)
A hello from me + Sanskrit etymologies reconstruction[edit]
@Kutchkutch: Hello! I hope you don't mind if I add this topic on your talk page. I want to ask how much of Proto-Indo-Aryan Iranian and European do you know? Because I create a lot of Sanskrit entries but I don't know about their etymologies at all. So do you know about them and if you do, can I leave a ping for you in the edit summary so you can add it? Nice to meet you, शब्दशोधक (talk) 11:32, 15 October 2020 (UTC)
- @शब्दशोधक: Hello, and nice to meet you as well! I'm not familiar enough with Proto-Indo-Aryan (PIA), Proto-Indo-Iranian (PII) and Proto-Indo-European (PIE) (yet) to add Sanskrit etymologies, so you would always have to ask for favours from other users such as User:Bhagadatta, User:AryamanA, User:Victar, etc. User:Bhagadatta has been giving you good advice and resources on PIA, PII and PIE. If you eventually want learn how to add Sanskrit etymologies and reconstruct those languages on your own, it would require spending some time to study those resources. If you're motivated enough, hopefully you'll become more knowledgeable about PIA, PII and PIE and contribute what you learn. Kutchkutch (talk) 12:19, 15 October 2020 (UTC)
@Bhagadatta: Thanks for responding to my ping requesting for the etymology of धन (dhána). On internet, there are many resources for PIE reconstruction and the 2 dictionaries you mentioned are also great. But yeah, for now it seems really complicated to me. I get the point of what you advised me to not go dive into etymologies for now. Maybe, first we should have all Sanskrit words here (or aim to) and then go on to “Proto-” languages. शब्दशोधक (talk) 13:13, 15 October 2020 (UTC)
@Kutchkutch: I want to know how much Sanskrit do you know as there is no Sanskrit on your Babel but you have made many edits to Sanskrit entries as I see in your contributions. शब्दशोधक (talk) 13:25, 15 October 2020 (UTC)
- @शब्दशोधक Contributions, communication and collaboration are much better indicators of knowledge compared to Babel boxes. If it helps, I could add
sa-1.
- @Bhagadatta Thanks for letting us know! It will be very interesting to see the etymology that you put there. If you can improve and/or correct the following, it would help both User:शब्दशोधक and I.
- I'm also interested in learning PIA, PII and PIE as well but learning about them requires a different approach. Although there's many resources available learning for PIE, many of primary sources such as IEW (Pokorny), LIV (Rix), etc. are all in German. While there are resources for PII, they're much fewer in number, and resources that focus on PIA are very hard to find. Thus, one could probably learn about PIE and avoid Wiktionary entirely, but searching for information about PIA inevitably leads to Wiktionary. Reconstructed languages focus on phonology and morphology rather than syntax and semantics.
- Learning about PIE would require a basic understanding of language families such as Italic, Celtic, Germanic, Balto-Slavic and Greek. PIE resources generally provide overviews of all these language families. The most important attested languages out of these language are Greek and Latin. Certain users can reconstruct Proto-Germanic and Proto-Balto-Slavic at an alarmingly fast speed.
- When there are varying standards for notation, the About pages clarify which notation Wiktionary uses (such as *y and *w for *i̯ and *u̯). Although the focus of WT:About Proto-Indo-Aryan is notation, it's much more useful compared to Proto-Indo-Aryan language (the Wikipedia page was created by User:AryamanA with an inventory of consonants that was later removed by User:Rua).
- Sometimes, there's multiple reconstructions possible for a single word depending on the time estimate, geographic estimate and the acceptance of various phenomena. For Indo-Iranian, some important phenomena appear to be Laryngeal theory, Grassmann's law, Pinault's law, Ruki sound law, Bartholomae's law, Brugmann's law and thorn clusters. User:Victar/Reflexes/Proto-Indo-Iranian, User:Bhagadatta/Rigveda in Proto-Indo-Aryan and Proto-Indo-Iranian, User:Bhagadatta/Indo-Iranian Vocabulary Innovations and User:Rua/Beowulf in Proto-Germanic are useful guides.
- Learning about PII would require a basic understanding of Old Iranian languages along with Sanskrit. A important aspect to remember when learning about Old Iranian languages is that there's more than one. The most attested Old Iranian languages are Avestan and Old Persian. Avestan is religious, while Old Persian is inscriptional. When Old Iranian languages are not sufficient for reconstructing PII, one may need to consider Middle Iranian (RC:Proto-Indo-Iranian/dʰr̥ždʰás) and Modern Iranian languages. Kutchkutch (talk) 13:17, 16 October 2020 (UTC)
@Kutchkutch: True! Now that you’ve already told me that your Sanskrit is sa-1, it won’t help me, but still it will help any other editor who doesn’t know this, so still consider adding it. शब्दशोधक (talk) 13:24, 16 October 2020 (UTC)
- @Kutchkutch, शब्दशोधक:
 Done. Also found quotations from the Rigveda for the two (slightly different) meanings. -- Bhagadatta(talk) 16:23, 16 October 2020 (UTC)
Done. Also found quotations from the Rigveda for the two (slightly different) meanings. -- Bhagadatta(talk) 16:23, 16 October 2020 (UTC)
@Bhagadatta: Thanks a lot!! शब्दशोधक (talk) 16:28, 16 October 2020 (UTC)
Sanskrit references[edit]
@Bhagadatta, Kutchkutch: I saw that you replaced {{R:MW}} with <references /> on the entry धन (dhána) and {{R:MW}} was already their with accurate page also. When I tried the same on समय (samayá), it didn’t happen as I thought and I had to revert that edit. Can any of you explain this? Thanks! शब्दशोधक (talk) 06:34, 17 October 2020 (UTC)
- @शब्दशोधक: If
{{R:MW}}is in the body of the entry as an WP:Inline citation, then <references /> is placed in the references section (see Help:Footnotes). I don't know what the significance of the space is since deleting it doesn't make any difference. - For attested terms, inline citations are a way of pointing out something unusual that is mentioned in the academic literature. However, for reconstructed terms, inline citations are required (see WT:Reconstructed_terms#References_from_etymologies).
- Nobody explained any of this to me, so I learned about this from observing other users (such as User:AryamanA at कच्चा (kaccā)). Kutchkutch (talk) 08:29, 17 October 2020 (UTC)
@Kutchkutch: Thanks for explaining :). So I get it that I have to always add {{R:MW}} because I am not at all familiar with quotations and citations so I never use it, which means I have to add {{R:MW|000}} with appropriate page number. Regards, शब्दशोधक (talk) 09:28, 17 October 2020 (UTC)
By the way I have added sa-1 to your Babel and I have changed Wikipedia to Wiktionary. If you have any problem feel free to revert. Also I have used {{#babel:}} instead of {{User sa-1}}. Hope you don’t mind :) शब्दशोधक (talk) 09:35, 17 October 2020 (UTC)
- So yeah, as Kutchkutch said, it's an inline reference which I used because I wanted to cite the MW dictionary for a specific part of the entry (in this case, the part of the etymology which claims that धन (dhana) literally means a running race) and not for the entry as a whole. In most cases, there's no need to inline it and you can put
{{R:sa:MW}}in the usual manner. I don't know the reason for the space in the tag either; I picked up the habit from copying pre-existing PIE entries which had it that way. -- Bhagadatta(talk) 11:26, 17 October 2020 (UTC)
@Bhagadatta, Kutchkutch: All right, my doubt is clear. Thank you very much both of you. And great to meet you, Kutchkutch, you are really patient explaining me all this. शब्दशोधक (talk) 13:12, 17 October 2020 (UTC)
Adminship[edit]
Hi,
I have nominated you for adminship. If you accept the nomination, please edit the acceptance section. --Anatoli T. (обсудить/вклад) 06:07, 26 December 2020 (UTC)
- @Atitarev Thanks for nominating both User:Bhagadatta and I! I've accepted your nomination. I'm really sorry about the late response. Regardless of exactly who and when it occurs, I definitely agree that there should more admins familiar with South Asian languages. Kutchkutch (talk) 13:10, 28 December 2020 (UTC)
Thank you for the Nomination[edit]
Hi! Just wanted to thank you for nominating me for the Autopatroller perms. It's the first time I've been given additional user group rights :) Also just out of curiosity, was that because of my edits on مسیت, where I kept getting warnings before publishing the edits?
-Taimoor Ahmed(گل بات؟) 22:20, 18 May 2021 (UTC)
- @Taimoorahmed11: Although there's always room for improvement in specific instances (as with any user or entry), as a whole, your editing has been good and has been occurring regularly, so keep up the good work. User_talk:Metaknowledge#زمین_اور_آسمان should serve as reminder that widespread changes such as introducing a new romanisation system should be discussed first. If the spelling of an entry is to be corrected and the previous spelling is not desired such as from گانو to گاؤں, it would help if the page is moved rather than creating a new entry to preserve the edit history as explained here: w:Help:How to move a page. Kutchkutch (talk) 09:07, 19 May 2021 (UTC)
- @Kutchkutch: I realised that I definitely shouldn't have made changes to the transliteration method without discussion, it was pretty ignorant of me in hindsight, I admit. When it comes to renaming pages, I didn't know it was preferred to just move pages, I didn't do that with گاؤں, just because I've never seen it written as گانو. Although, I will bear that in mind next time, so that the history can be preserved. Also, if let's say, I had moved the page rather than requesting a deletion and creating a new page, and a separate page was required for the word گانو, would it simply be a case of removing the redirect?
-Taimoor Ahmed(گل بات؟) 10:04, 19 May 2021 (UTC)
- @Kutchkutch: I realised that I definitely shouldn't have made changes to the transliteration method without discussion, it was pretty ignorant of me in hindsight, I admit. When it comes to renaming pages, I didn't know it was preferred to just move pages, I didn't do that with گاؤں, just because I've never seen it written as گانو. Although, I will bear that in mind next time, so that the history can be preserved. Also, if let's say, I had moved the page rather than requesting a deletion and creating a new page, and a separate page was required for the word گانو, would it simply be a case of removing the redirect?
- @Taimoorahmed11: If a a separate page had been required for گانو, and a soft redirect is needed that lets a reader know why there is a redirect, then see Wiktionary:Redirections and the templates listed at Category:Form-of templates. For example:
- If the soft redirect is a common misspelling that meets Wiktionary:Misspellings, then
{{misspelling of}}could be used - If the soft redirect is an alternative form that is not a common misspelling, then
{{alternative form of}}could be used
- If the soft redirect is a common misspelling that meets Wiktionary:Misspellings, then
- @Taimoorahmed11: If a a separate page had been required for گانو, and a soft redirect is needed that lets a reader know why there is a redirect, then see Wiktionary:Redirections and the templates listed at Category:Form-of templates. For example:
- If the etymology and references are the same as the primary entry, then the entry could look like:
- with only the headword(s), definition line(s) and possibly declension. And always remember to use w:Help:Show preview to minimise minor errors from showing up the w:Help:Page history. Kutchkutch (talk) 10:38, 19 May 2021 (UTC)
- @Kutchkutch: Noted, thank you!
-Taimoor Ahmed(گل بات؟) 12:51, 19 May 2021 (UTC)
- @Kutchkutch: Noted, thank you!
MB entries[edit]
Hey, you need not mass-create Middle Bengali entries. I shall sooner or later be creating a module for Old & Middle Bengali pronunciations; if you go on creating entries like this then I would have a tough time manually adding the IPA in all entries (because the templets would need a parameter). Thank you. ·~ dictátor·mundꟾ 10:05, 14 July 2021 (UTC)
- @Inqilābī I'm surprised that you have perceived these entries to be mass-created because I felt that they were created at a very leisurely pace. Thanks for sharing that you plan to create pronunciation modules for Old and Middle Bengali.
- From my experience with working on the phonological details of MOD:mr-IPA in collaboration with AryamanA, the entry creation and deployment of a pronunciation module even with manual intervention do not need necessarily have to be simultaneous especially since entry creation is a higher priority even if the pronunciation module is not on every applicable entry. (There are only 791 instances of T:mr-IPA out of 1,878 lemmas with some manual intervention).
- There are currently 30 lemmas in Category:Middle Bengali lemmas.
- Even if a handful are created every few days, would it really be a lot of work to maintain them?
- Would it be possible for you to provide some of the phonological details that would be used for the testcases? Kutchkutch (talk) 16:27, 14 July 2021 (UTC)
Page parameter[edit]
Hi. Just wanted to tell you that it’s unnecessary to add the page no. to a reference templet when there’s already a link to the reference entry. As far as I remember, @Bhagadatta also does not add it in such cases. And why this is unneeded, is simply due to the fact that the reader is already directed to the entry where the information is provided, it’s not worthwhile to lead the reader to the whole page, is it? ;) And more importantly, I do not think a reference templet is supposed to have multiple links (not counting a WP link), anyway. Have a good day. ·~ dictátor·mundꟾ 13:32, 20 August 2021 (UTC)
- @Inqilābī: Some reasons for having both the entry link and page link could include:
- The entry link doesn't work or the output of the link may vary by device, operating system or IP address
- Entries before and after the primary entry may be of relevance
- If links are digitised versions of physical books, a reader with a hard copy or scanned copy that was used to create the digitised versions could use the page number to look up the entry in the physical book.
- Does it actually say 'a reference templet is not supposed to have multiple links' on a page such as Wiktionary:Reference templates? Kutchkutch (talk) 17:07, 20 August 2021 (UTC)
- Haha, dictator mundi, enough of your weird ideas. FYKI, Bhagadatta also gave the page for CDIAL at राजपुत्र, so I request you to think before you say something like that! And I [j]ust wanted to tell you that it’s unnecessary to add [your strange ideas to discussions which keep popping up in your mind]. And mo[st] importantly, [it is you who] do[es] not think a reference templ[ate] is not supposed to have multiple links, so I do not think we all should follow that. Have a [nice] day. Svārtava2 • 15:49, 21 August 2021 (UTC)
- @Sgconlaw: Since you are the master of templates, I would like to ask one thing: is it a good idea to have multiple links to a single reference, as in the Turner reference at राजपुत्र? ·~ dictátor·mundꟾ 13:43, 7 September 2021 (UTC)
- Even if the master of templates thinks it isn't a good idea to have multiple links to a single reference, I'm not gonna follow it or tolerate their removal by you unless
it [is] actually sa[id] 'a reference templ[ate] is not supposed to have multiple links'[in the words of Kutchkutch]. —Svārtava2 • 14:57, 7 September 2021 (UTC)
- Even if the master of templates thinks it isn't a good idea to have multiple links to a single reference, I'm not gonna follow it or tolerate their removal by you unless
- [In reply to diff:] To confirm, I am involved in this discussion as I also believe linking the page number is helpful, I have done that before, and am here to defend that. —Svārtava2 • 06:47, 8 September 2021 (UTC)
- I am not interested in editwarring, but I feel bad that Sgconlaw has been scared away from this post because of your trolly comments. I was only wanting more input to this good discussion, not your silly words. By the way, your comment about Bhagadatta was misleading— if only you had cared to see things carefully instead of being overly eager to attack me! ·~ dictátor·mundꟾ 10:06, 8 September 2021 (UTC)
block please[edit]
Hi there! I'm Wonderfool (talk • contribs), everyone's favourite vandal. It's time to get rid of this account and get a ew new ones Wubble You (talk) 12:45, 29 August 2021 (UTC)
Saraiki Writing Systems[edit]
Hi @Kutchkutch, hope you can help me in this. It seems Devanagari is listed as a writing system for the Saraiki language, and a user had even added some modified Devanagari characters as part of the "Saraiki Devanagari Alphabet" (which I have removed). The only thing I can't change is the Module:languages/data3/s. Would it be appropriate for you to remove this please?
-Taimoor Ahmed(گل بات؟) 22:54, 10 October 2021 (UTC)
- @Taimoorahmed11: The scripts listed in the data modules Module:languages are intended to be all scripts that have ever been used for a particular language outside of experimentation. According to various statements online:
- The Devanagari and Gurmukhi scripts, written from left to right, were used by Sikhs and Hindus
- Though not used in present-day Pakistan, there are still emigrant speakers in India who know the Devanagari or Gurmukhi scripts for Saraiki
- https://www.ethnologue.com/contribution/318286
- In India Saraiki as native language is in
- Rajasthan: Ganganagar district, Khajuwala and Pugal
- Punjab: Firozpur district, Fazilka; Haryana: Sirsa and Fatehabad districts.
- But as migrated from Pakistan are in Dehli, Punjab, Haryana
- https://www.omniglot.com/writing/saraiki.htm
- there were 109,000 speakers of Saraiki in the states of Haryana, Punjab and Rajasthan in northern India in 2011
- Although there is no direct evidence and the accuracy of Omniglot's presentation is uncertain, this suggests that Saraiki was probably in written in Devanagari at some point in time, so perhaps the Devanagari script can remain at Module:languages/data3/s. However, entries for the modified Devanagari characters such as at ऱ and ॾ़ & Saraiki words in Devanagari should be omitted until direct evidence can be found.
- @Kutchkutch Ah understood. I understand that Omniglot has the tendency to create their own alphabets for languages - I'm aware they also did this for Shahmukhi (though I can't find it right now), where they supposedly made an alphabet consisting of more characters than needed, hence why I don't consider it reliable.
-Taimoor Ahmed(گل بات؟) 07:06, 12 October 2021 (UTC)
- @Kutchkutch Ah understood. I understand that Omniglot has the tendency to create their own alphabets for languages - I'm aware they also did this for Shahmukhi (though I can't find it right now), where they supposedly made an alphabet consisting of more characters than needed, hence why I don't consider it reliable.
- Regarding Saraiki coverage:
- Have you found any dictionaries that are more recent than Template:R:pnb:Jatki? Support for the Multani script (analogous to Khudawadi) should eventually be added such as a transliteration module, a typing aid and a script parameter for
Template:srk-nounTemplate:skr-noun. Kutchkutch (talk) 10:38, 11 October 2021 (UTC)
- Have you found any dictionaries that are more recent than Template:R:pnb:Jatki? Support for the Multani script (analogous to Khudawadi) should eventually be added such as a transliteration module, a typing aid and a script parameter for
- @Kutchkutch Unfortunately I have not seen any recent dictionaries being published, at least not ones that I could find online. Everywhere that I've looked, I could only find Template:R:pnb:Jatki (which needs to be changed to Template:R:srk:Jatki).
-Taimoor Ahmed(گل بات؟) 07:06, 12 October 2021 (UTC)
- @Kutchkutch Unfortunately I have not seen any recent dictionaries being published, at least not ones that I could find online. Everywhere that I've looked, I could only find Template:R:pnb:Jatki (which needs to be changed to Template:R:srk:Jatki).
- @Taimoorahmed11: Sorry about the typo above. The correct code for Saraiki is
skrand notsrk, which is the language code for Category:Serudung Murut language. Template:R:srk:Jatki has been moved to Template:R:skr:Jatki. Is Saraiki Education books of any use to you? Kutchkutch (talk) 12:02, 13 October 2021 (UTC)- Duh! I should've seen that myself as well! No worries! Also I've come across the website before but didn't necessarily pay any attention to it, though it is definitely useful. I might start add Saraiki lemmas from the PDF files, since I'm trying to expand both Saraiki and Punjabi lemmas on Wiktionary.
-Taimoor Ahmed(گل بات؟) 12:59, 13 October 2021 (UTC)
- Duh! I should've seen that myself as well! No worries! Also I've come across the website before but didn't necessarily pay any attention to it, though it is definitely useful. I might start add Saraiki lemmas from the PDF files, since I'm trying to expand both Saraiki and Punjabi lemmas on Wiktionary.
- @Taimoorahmed11: Sorry about the typo above. The correct code for Saraiki is
Devanagari in Prakrit declensions[edit]
Hi. I would like the Prakrit declension templates be able to generate inflections for a given Devanagari form, similar to the {{pi-decl-noun}} can. [19] was my first try to make the module:pra-decl/noun workable for Devanagari script. It was able to do the job, but not show the transliterations, perhaps because pmh can't transliterate Devanagari ({{m|pmh|पुत्तो}} gives Lua error in Module:parameters at line 95: Parameter 1 should be a valid language or etymology language code; the value "pmh" is not valid. See WT:LOL and WT:LOL/E. w/o translit). I tried changing that code to inc-pra at lines 103, 104, but apparently the hyphen in between was causing error (Error: [103:19] '(' expected near '-'). So could you improve the existing module or create a new module for Devanagari? —Svārtava [t•c•u•r] 16:17, 10 November 2021 (UTC)
- Svartava2 Ideally both/all scripts would be handled by a single module that detects the input script and treats it as a variable. However, until this is done, separate modules and perhaps templates for each script could be used.
_could be used as a substitute for-since-is not permitted for naming functions. You could try pinging the users who have edited Module:pi-decl/noun to see if they have any interest in improving the existing module. Kutchkutch (talk) 13:50, 12 November 2021 (UTC)- (pinging Octahedron80, RichardW57) I'm not sure if
inc_prawould be recognised as a valid language code. For now, a temporary solution would be to create modules like Module:pra-decl-mah-Deva etc. till more knowledgeable module coders like AryamanA, Benwing2 can step up. —Svārtava [t•c•u•r] 14:17, 12 November 2021 (UTC)- I tried for a separate module for Maharastri Prakrit Devanagari declension, but that has errors and isn't working. Can you please see and fix? —Svārtava [t•c•u•r] 16:37, 12 November 2021 (UTC)
- @Svartava2: You've got all sorts of problems with how you're passing language around. The first problem is that language code, which is a string, needs to be quoted as a literal, so "inc-pra", not
inc-pra. Hyphens aren't allowed in Lua variable names, so the latter will be treated as an expression using global variables, which if you are lucky will cause the parser to choke. The second, is that some of the functions, like full_link(), need a language object as an argument.
- @Svartava2: You've got all sorts of problems with how you're passing language around. The first problem is that language code, which is a string, needs to be quoted as a literal, so "inc-pra", not
- I tried for a separate module for Maharastri Prakrit Devanagari declension, but that has errors and isn't working. Can you please see and fix? —Svārtava [t•c•u•r] 16:37, 12 November 2021 (UTC)
- (pinging Octahedron80, RichardW57) I'm not sure if
- The following snippet has several problems of style at the very least.
function export.show(frame, lang)
local args = frame:getParent().args
local g = args[1]
local word = args[2] or PAGENAME
local m_lang = require("Module:languages").getByCode(lang)
- Firstly, the name lang is usually reserved for languages, and if often used as the name of the variable holding the language object. Similarly m_lang is normally the pointer to a module. So, unless your ambitions for this code extend beyond a single language, I would expect the last line to look like
local lang = require("Module:languages").getByCode("inc-pra"). The value returned designates the language object - almost certainly a pointer to a relevant table. --RichardW57 (talk) 19:24, 12 November 2021 (UTC)
- Firstly, the name lang is usually reserved for languages, and if often used as the name of the variable holding the language object. Similarly m_lang is normally the pointer to a module. So, unless your ambitions for this code extend beyond a single language, I would expect the last line to look like
- In the snippet
local word_tr = m_translit.tr(word, m_lang, "Deva"), the second argument should be a language code, not object. I think this won't cause you any problems yet. However, you should be using, using your current variable names,m_lang:transliterate(word, "Deva"). Prakrit is equipped with transliteration for Devanagari, Brahmi and Kannada.--RichardW57 (talk) 19:55, 12 November 2021 (UTC)- @RichardW57: Thanks for the improvements. Would you be able to yourself edit module and make the corrections? —Svārtava [t•c•u•r] 08:22, 13 November 2021 (UTC)
- @Svartava2: Probably, though tonight I'm currently involved in some intensive editing on Wikipedia. Do you have a template to invoke the module? If I read your code right, you use, as the Pali module does, parameters passed to that script. Are you expecting the declension template to add parameters? Some of the Sanskrit templates with two layers of parameters - editor designed and fixed.
- @RichardW57: Thanks for the improvements. Would you be able to yourself edit module and make the corrections? —Svārtava [t•c•u•r] 08:22, 13 November 2021 (UTC)
- In the snippet
- There seem to be some design issues that you haven't addressed:
- Irregular declension. That's an issue for many languages, even Latin.
- Multiple prakrits. You may need footnotes, and possibly even footnotes defined in the template invocation, for the previous point. I've been pondering how to provide them for Pali with an editor-tolerable interface.
- Spelling coordination between stem and affixes. While at least Romanisation seems to be reversible (it isn't for all Pali scripts), are homorganic nasals (as in the ablative plural) always written with anusvara?
You may be planning to bolt them on later. --RichardW57 (talk) 18:11, 13 November 2021 (UTC)
RichardW57, RichardW57m The presentation of declension in Prakrit treatises is often very scattered, confusing and unstandardised. Until a way forward is determined for multiple lects & additional data, the improvement should probably be very similar to the current design, which is:
- The module currently only supports regular declension for the Maharastri and Magadhi lects
- Maharastri irregular declension can be entered manually using Template:pmh-decl-noun-irregular
- There is template for Sauraseni a-stem masculine nouns at Template:psu-decl-noun-a-m
- 𑀅𑀕𑁆𑀕𑀺 is an example of an entry that shows the declension for both lects with two separate tables and templates:
{{pmh-decl-noun}}and{{inc-mgd-decl-noun}}
- The templates have a parameter for gender.
- The data for each table located at:
- 𑀅𑀕𑁆𑀕𑀺 is an example of an entry that shows the declension for both lects with two separate tables and templates:
- Someone should document how to list multiple accusative plurals. --RichardW57 (talk) 15:29, 21 November 2021 (UTC)
- Regarding homorganic nasals, it seems to be the norm to use
ṃforhiṃtoandmformmi. Kutchkutch (talk) 20:16, 13 November 2021 (UTC)- But what if the stem is written with -nt- or -ṃm-? Norms aren't always followed.--RichardW57 (talk) 15:29, 21 November 2021 (UTC)
- @RichardW57, Kutchkutch: A template,
{{pmh-decl-noun-Deva}}could be created once the module is made working. I have very little knowledge about modules, so it would be very nice if any of you could fix it. For now, I'm thinking of specific templates like{{psu-decl-noun-a-m}}. They can be replaced once we have the module working. —Svārtava [t•c•u•r] 11:05, 21 November 2021 (UTC)- @Svartava2: I've got the module working for basic Devanagari functionality. For non-Devanagari functionality, you just need to determine the script and use function tr() in Module:sa-convert to convert from Devanagari to the target script. To test the changes, I knocked up a template Template:User:RichardW57/pra-decl-noun and invoke it in my sandbox. I reverted to the Pali habit of specifying gender as
|g=rather than as the first parameter. --RichardW57 (talk) 13:23, 21 November 2021 (UTC)- @RichardW57: Thanks a lot!! I have used the already existing
{{pmh-decl-noun}}for invoking the (new) module, and it will invoke the appropriate Brahmi or Devanagari declension module based on the page title's script. However for that I had to change the|g=back to|1=only for consistency: its strange to have to write{{pmh-decl-noun|m}}if Brahmi and{{pmh-decl-noun|g=m}}if Devanagari (now it is too late to change the parameter in the Brahmi module). Thanks again, it's a step towards making the Prakrit entries useful and improving Prakrit in Devanagari. —Svārtava [t•c•u•r] 14:13, 21 November 2021 (UTC)- @Svartava2: One can always do a smooth switch-over by checking for the presence of
|g=. It does seem wrong, though, to have three separate modules for Brahmi, Devanagari and Kannada. By the way, the language label in the output needs to be changed - you need to record the dialect. --RichardW57 (talk) 15:29, 21 November 2021 (UTC)- RichardW57 Are you referring to [20]? —Svārtava [t•c•u•r] 15:58, 21 November 2021 (UTC)
- @Svartava2: Yes, that was quick. Does it already make sense to delete my test rigs, i.e. template and section of sandbox? Getting rid of my template will need an admin to speedily delete it. Technically, I think you should have moved the module from user module space to main module space, rather than copy it, so as to preserve the attributions. --RichardW57 (talk) 19:47, 21 November 2021 (UTC)
- @RichardW57: I think you can delete your test template and sandbox section. I did think of moving the module, but that's my sandbox with some bit of other history and it might not be preferable to have it on the actual module. —Svārtava [t•c•u•r] 07:37, 22 November 2021 (UTC)
- @Svartava2: Yes, that was quick. Does it already make sense to delete my test rigs, i.e. template and section of sandbox? Getting rid of my template will need an admin to speedily delete it. Technically, I think you should have moved the module from user module space to main module space, rather than copy it, so as to preserve the attributions. --RichardW57 (talk) 19:47, 21 November 2021 (UTC)
- RichardW57 Are you referring to [20]? —Svārtava [t•c•u•r] 15:58, 21 November 2021 (UTC)
- @Svartava2: One can always do a smooth switch-over by checking for the presence of
- @RichardW57: Thanks a lot!! I have used the already existing
- @Svartava2: I've got the module working for basic Devanagari functionality. For non-Devanagari functionality, you just need to determine the script and use function tr() in Module:sa-convert to convert from Devanagari to the target script. To test the changes, I knocked up a template Template:User:RichardW57/pra-decl-noun and invoke it in my sandbox. I reverted to the Pali habit of specifying gender as
Spam[edit]
An anon added a link to the gentlemen's club page, you should hide the revision text. 37.110.218.43 09:51, 30 November 2021 (UTC)
Unlike Devanagari, Kannada distinguishes b/w the long and short o & e. Although all instances of Sanskrit ओ are written as ಓ in Kannada, would the Prakrit short o, preceding geminated consonants be written as ಒ? Would ಬೋಲ್ಲಇ then be ಬೊಲ್ಲಇ? -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 11:30, 4 December 2021 (UTC)
- Bhagadatta Yes, according to prakrit.info/prakrit, and prakrit.info/prakrit is currently the only reference being consulted for the Kannada script (unless you can access the Kannada script dictionary that you mentioned at Template talk:pra-noun).
- See line 394 of the Gāhā Sattasaī:
- Kannada script:
- ಮರಗಅಸೂಈವಿದ್ಧಂ ವ ಮೊ.ತ್ತಿಅಂ ಪಿಅಇ ಆಅಅಗ್ಗೀ.ವೋ. ಮೋ.ರೋ ಪಾಉಸಆಲೇ ತಣಗ್ಗಲಗ್ಗಂ ಉಅಅಬಿಂದುಂ
- Module:kn-translit
- maragaasūīviddhaṃ va mo.ttiaṃ piai āaaggī.vō. mō.rō pāusaālē taṇaggalaggaṃ uaabinduṃ
- Kannada script:
- However, the Devanagari script at prakrit.info/prakrit also uses ऒ (o) instead of ओ (ō) for short o:
- […] मॊ […] आअअग्गीवो मोरो
- Module:mai-translit
- […] mo […] āaggīvō mō.rō
- For Devanagari, this would not conform to Wiktionary's current practice for Prakrit page titles. This is comparable to य़ for the hiatus filler at Template talk:pmh-decl-adj#Hiatus filler. Bhagadatta Could the additional precision provided by ऎ/ऒ and य़ be indicated in the
|headword=parameter instead of the page title? Kutchkutch (talk) 19:01, 4 December 2021 (UTC)- I didn't remember bringing it up in May! Yes, ऎ/ऒ and य़ could be shown in the headword. My reasoning for using the short o & e for Kannada but not for Devanagari is that ऎ and ऒ are not universal within Devanagari, only some languages that use Devanagari use it. On the other hand, Kannada script always makes the distinction between the long & short o. So that could be an argument in favour of using the short o & e for Kannada but not for Devanagari. -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 01:18, 5 December 2021 (UTC)
- Bhagadatta: Since
Kannada script always makes the distinction between the long & short o, having ಎ & ಒ in page titles is fine. Several modules/templates may need to be edited to support this and using ऎ/ऒ & य़ in headwords. For example, they would need to be automatically transliterated as ĕ/ŏ & ẏ and be added to Module:typing-aids. - Unfortunately, there appears to be no way to indicate the hiatus filler in the Brahmi script. Could
- the hiatus filler be represented in the Kannada script as ಯ಼ — ಯ + ಼ (U+0CBC KANNADA SIGN NUKTA) in headwords and
- short e & o be represented in Brahmi as 𑁱 (U+11071 BRAHMI LETTER OLD TAMIL SHORT E) and 𑁴 (U+11072 BRAHMI LETTER OLD TAMIL SHORT O) headwords
- ? Kutchkutch (talk) 20:28, 5 December 2021 (UTC)
- I oppose य़, it's weird and rare. Can you cite some instances of it? Most of the Maharastri Prakrit -y- are just hiatus fillers when they are in place of क/ग/च/ज/त/द > अ. —Svārtava [t•c•u•r] 16:19, 6 December 2021 (UTC)
- Svartava2 y and ẏ are differentiated as distinct characters in Woolner and Pischel.
- I oppose य़, it's weird and rare. Can you cite some instances of it? Most of the Maharastri Prakrit -y- are just hiatus fillers when they are in place of क/ग/च/ज/त/द > अ. —Svārtava [t•c•u•r] 16:19, 6 December 2021 (UTC)
- Bhagadatta: Since
- I didn't remember bringing it up in May! Yes, ऎ/ऒ and य़ could be shown in the headword. My reasoning for using the short o & e for Kannada but not for Devanagari is that ऎ and ऒ are not universal within Devanagari, only some languages that use Devanagari use it. On the other hand, Kannada script always makes the distinction between the long & short o. So that could be an argument in favour of using the short o & e for Kannada but not for Devanagari. -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 01:18, 5 December 2021 (UTC)
- See Woolner page 12:
- In place of the omitted consonant was pronounced a weakly articulated ya (laghu-prayatnatara-ya-kāra). This was weaker than the य of Sanskrit or Magadhi, and was not expressed in writing, except in manuscripts written by the Jains, e.g., hiẏaẏa. = hṛdaya.
- See Woolner page 12:
- See Pischel page 51:
- In places of consonants that drop inside a word, between two vowels, there develops as a glide sound ya, that is written in all the dialects in Jaina manuscripts, and it is a distinctive feature of AMg., JM. and JS. (§187), In this grammar it has been transcribed by ẏa.
- See Pischel page 51:
- See Pischel page 141:
- In place of the consonants that have dropped off a weakly articulated (laghu-prayatnatara-ya-kāra) is uttered, that is indicated in this grammar by ẏa Except in the manuscripts written by Jainas this ẏa is not indicated. Hemachandra teaches that it comes in between a and ā only.
- See Pischel page 141:
- y is an integral character that cannot be omitted. However, ẏ is purely aesthetic. Since y and ẏ have two distinct purposes, and all the lects are merged as a single language, it would be helpful to make a prescriptive distinction between y and ẏ regardless of the attestation status of ẏ in Devanagari/Kannada/Brahmi.
- It has an equivalent in Eastern Nagari as য় (ẏo). See Wikipedia_talk:Indic_transliteration#य़?:
- this letter is simply the Devanagari equivalent of Bengali-Assamese য়, which is used to mark hiatus between vowels, or to mark [e] when in coda position. This is different from the Bengali-Assamese য, which is pronounced [dʒ] or [z] depending on the language, dialect, and speaker.
- It has an equivalent in Eastern Nagari as য় (ẏo). See Wikipedia_talk:Indic_transliteration#य़?:
- Also, observe Sanskrit y → Prakrit ẏ in Sanskrit indriya → Prakrit indiẏa. See य़ at https://aksharamukha.appspot.com/describe/Devanagari
- This issue was first brought up at Talk:𑀯𑀅𑀁:
- shouldn't the Brahmi orthography have something that indicates the ẏ?
- The only possibility is a written regular y (but that wouldn't make sense, then it would be vayaṃ) or an unwritten glide i. I think the i makes sense, because e.g. Sauraseni is known to have vaaṃ.
- This issue was first brought up at Talk:𑀯𑀅𑀁:
- Bhagadatta What the discussion at Talk:𑀯𑀅𑀁 and
Unfortunately, there appears to be no way to indicate the hiatus filler in the Brahmi script.
- means is that
- Template:hiatus-filler form of would only be used for Devanagari and Kannada-script terms with the hiatus filler य़/ಯ಼ in the headword
- pages such as 𑀓𑀬 would not exist, and their Ardhamagadhi & Jain Maharastri contents would have to be moved to the 𑀬-less spelling and/or the corresponding Devanagari/Kannada-script pages containing the hiatus filler य़/ಯ಼ in the headword. Kutchkutch (talk) 21:19, 6 December 2021 (UTC)
- But then, most of the -y-s are in fact hiatus-fillers! So most Brahmi 𑀬-containing spellings would be removed? —Svārtava [t•c•u•r] 08:02, 7 December 2021 (UTC)
- Bhagadatta What the discussion at Talk:𑀯𑀅𑀁 and
- I think that writing a word containing a short vowel using a spelling that expressly marks this vowel as long constitutes a greater degree of wrongness than leaving off a diactritic that is anyway not in widespread use. But as Kutchkutch said, it'll also mean we will need to change several modules. I don't know of a good solution yet. -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 08:47, 8 December 2021 (UTC)
An anon put some puerile crap into this entry...has since been undone but the revision should be hidden. 37.110.218.43 13:49, 9 December 2021 (UTC)
Old punjabi is not an actual language[edit]
So stop altering the spellings of punjabi words and calling it old punjabi IMPNFHU (talk) 16:40, 9 December 2021 (UTC)
- @IMPNFHU: Old Punjabi is indeed an actual language. Compare Old Hindi, Old Marathi, Old Gujarati.
- 2000, Gopal Haldar, Languages of India, →ISBN, page 149:
- The age of Old Punjabi: up to 1600 A.D. […] It is said that evidence of Old Punjabi can be found in the Granth Sahib.
- 2021, Zhanna Chalabayeva, Red Indian Sun, →ISBN:
- The Adi Granth is written in Old Punjabi language. [= Old Punjabi is the language of the Adi Granth]
- So please stop removing valid and sourced Old Punjabi entries. —Svārtava [t•c•u•r] 04:21, 10 December 2021 (UTC)
Sikh scriptures are not written in punjabi IMPNFHU (talk) 08:36, 10 December 2021 (UTC)
Old punjabi is not an actual language according to the punjabi university of patiala IMPNFHU (talk) 08:38, 10 December 2021 (UTC)
There's no mention of it on punjabi language article on wikipedia either IMPNFHU (talk) 08:56, 10 December 2021 (UTC)
- Discussion moved to User_talk:IMPNFHU#Reverting_and_Removal_of_inc-opa.
- Svartava2 Should there be an entry for Old Punjabi similar to Middle Assamese and Middle Bengali using those quotations? 00:28, 30 December 2021 (UTC)
I think you intended to hide Special:MobileDiff/49152758 rather than Special:MobileDiff/63601797. I don't know if it's possible or not (since it's an earlier revision and other edits have been made after it) but the former is the promotional one and the latter seems okay AFAIR (also note that it hasn't been undone). —Svārtava [t•c•u•r] 17:01, 29 December 2021 (UTC)
- Svartava2
 Fixed Kutchkutch (talk) 00:28, 30 December 2021 (UTC)
Fixed Kutchkutch (talk) 00:28, 30 December 2021 (UTC)
- It is still visible in permalinks. If possible, please remove it. —Svārtava [t•c•u•r] 15:41, 30 December 2021 (UTC)
How we will see unregistered users[edit]
Hi!
You get this message because you are an admin on a Wikimedia wiki.
When someone edits a Wikimedia wiki without being logged in today, we show their IP address. As you may already know, we will not be able to do this in the future. This is a decision by the Wikimedia Foundation Legal department, because norms and regulations for privacy online have changed.
Instead of the IP we will show a masked identity. You as an admin will still be able to access the IP. There will also be a new user right for those who need to see the full IPs of unregistered users to fight vandalism, harassment and spam without being admins. Patrollers will also see part of the IP even without this user right. We are also working on better tools to help.
If you have not seen it before, you can read more on Meta. If you want to make sure you don’t miss technical changes on the Wikimedia wikis, you can subscribe to the weekly technical newsletter.
We have two suggested ways this identity could work. We would appreciate your feedback on which way you think would work best for you and your wiki, now and in the future. You can let us know on the talk page. You can write in your language. The suggestions were posted in October and we will decide after 17 January.
Thank you. /Johan (WMF)
18:14, 4 January 2022 (UTC)
Hindustani descendants by script?[edit]
Since we treat Hindi and Urdu as separate languages, I'm not sure
- Hindustani:
- Arabic:
- Devanagari:
- Kaithi:
is the best method to use in descendants section. I would prefer
- Hindustani:
- Hindi:
- Devanagari:
- Kaithi:
- Urdu:
- Hindi:
- Also, are the Kaithi forms you have recently added all attested? —Svārtava (t/u) • 14:52, 22 February 2022 (UTC)
- @Svartava Regarding the descendants section:
- I agree with
since we treat Hindi and Urdu as separate languages, it would be helpful to showHindiandUrduunderHindustani. Although Kaithi is a Brahmic script like Devanagari, it is not exclusive to Hindi and was also used for the Urdu register of Hindustani according to:
- I agree with
- @Svartava Regarding the descendants section:
- https://www.unicode.org/L2/L2008/08194-n3389-kaithi.pdf
Kaithi was used to write Urdu or the “Hindustani” lingua franca, although now the Perso-Arabic script is associated with UrduKaithi was used for writing Urdu in the law courts of Bihar when it replaced Perso-Arabic as the official script during the 1880s. The majority of extant legal documents from Bihar from the British period are in Urdu written in Kaithi
- https://www.unicode.org/L2/L2008/08194-n3389-kaithi.pdf
- See also Wiktionary:About Hindi:
Hindi on Wiktionary is any instance of Hindustani in the Devanagari script.
- So would your preference change after evaluating these statements, or would your preference remain the same?
- See also Wiktionary:About Hindi:
- Regarding the attestation of Kaithi:
scribes propagated the script for both official and routine purposeThe use of Kaithi for administrative purposes is attested from at least the 16th century through the first decade of the 20th century.Kaithi was also used for routine writing, commercial transactions, correspondence, and personal records.Despite its characterisation as a secular script, Kaithi was also used for writing religious and literary manuscripts. It appears synchronically with Devanagari and Persian in administrative, literary, and religious manuscripts.
- Regarding the attestation of Kaithi:
- Therefore, as long as the conversion from Devanagari to Kaithi is accurate, attestation for every term seems unnecessary just like Brahmi and Modi. Kutchkutch (talk) 09:11, 6 March 2022 (UTC)
- Kaithi script entries or even mentions seem unprecedented, though; and combined with the fact that a lot of Hindi and Urdu terms are attested after the first decade of the 20th century. So I don't think having (correct) Kaithi equivalents of all such terms is a good idea and I still think maybe the attested ones should only get an entry. —Svārtava (t/u) • 09:31, 6 March 2022 (UTC)
- Therefore, as long as the conversion from Devanagari to Kaithi is accurate, attestation for every term seems unnecessary just like Brahmi and Modi. Kutchkutch (talk) 09:11, 6 March 2022 (UTC)
- AryamanA:
Does Bhojpuri still use the Kaithi script? - DerekWinters:
There are those who still use it, although it is not standard for government purposes. We can make it an alternate script for Bhojpuri.
- AryamanA:
- AryamanA:
all the Hindi belt languages used Kaithi to some extent until independence and government adoption of Devanagari.
- AryamanA:
- There are several Kaithi script entries in:
- None of these terms appear to be specifically attested in the Kaithi script. So does
I don't think having (correct) Kaithi equivalents of all such terms is a good idea and I still think maybe the attested ones should only get an entry.
- extend to these languages as well, or is this sentiment only for Hindi/Urdu? (User:Anisht dev) Kutchkutch (talk) 10:28, 6 March 2022 (UTC)
- I'm personally not concerned about the Magahi/Bhojpuri entries; what I am concerned about is creation of new Hindi/Urdu entries in Kaithi script for unattested Kaithi forms. By the way, what about joining Discord as in the section below? —Svārtava (t/u) • 10:33, 6 March 2022 (UTC)
- None of these terms appear to be specifically attested in the Kaithi script. So does
Discord[edit]
Would you like to join WT:Discord? —Svārtava (t/u) • 06:50, 26 February 2022 (UTC)
- +1. It makes communications very easy. -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 07:07, 26 February 2022 (UTC)
Old Punjabi, Old & Middle Bengali[edit]
I'm curious as to why you have stopped working in these languages. I used to really enjoy your work in archaic New Indo-Aryan. -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 09:33, 8 March 2022 (UTC)
- @Bhagadatta: Thanks for observing and appreciating the work that I have previously done in those languages. Sorry about the late response(s) (@Svartava2). Since I've been travelling, my internet connection has been less reliable than usual and I've had less spare time. I intend to continue editing more frequently soon, and I'll also consider taking a closer look at Discord.
- Regarding Old Punjabi:
- Other than the Shahmukhi equivalents, adding coverage of Old Punjabi using
{{R:inc-opa:Glossary}}and{{R:inc-opa:SGGS}}is usually straightforward.
- Other than the Shahmukhi equivalents, adding coverage of Old Punjabi using
- Regarding Old Punjabi:
- Regarding Old & Middle Bengali:
- At User_talk:Kutchkutch#MB_entries Inqilābī said:
- Regarding Old & Middle Bengali:
Hey, you need not mass-create Middle Bengali entries... if you go on creating entries like this then I would have a tough time manually adding the IPA in all entries (because the templets would need a parameter). Thank you.
- And at User_talk:Inqilābī#Old/Middle_Bengali, I asked:
is it now okay to start creating them again, or do you still need time
- However, Inqilābī has not responded (@Inqilābī). Kutchkutch (talk) 05:51, 19 March 2022 (UTC)
- Oh. I hadn't seen that discussion. But I fail to see how increasing the coverage for Old & Middle Bengali will increase the workload if and when the templates are completed; sure, they will require manual input of a parametre if the page already exists but if it doesn't then the task will be to create the page, including the pronunciation and the other info right? Surely the workload is more in the second case. In any event, there are many instances of not all lemmas of a language not having IPA, including Sanskrit and Hindi. -- 𝓑𝓱𝓪𝓰𝓪𝓭𝓪𝓽𝓽𝓪(𝓽𝓪𝓵𝓴) 10:43, 26 March 2022 (UTC)
- However, Inqilābī has not responded (@Inqilābī). Kutchkutch (talk) 05:51, 19 March 2022 (UTC)
@Bhagadatta, Inqilābī: I certainly agree with:
I fail to see how increasing the coverage for Old & Middle Bengali will increase the workload if and when the templates are completed:- if the entry exists, then the task will be to add new pronunciation info if it is missing or edit any existing pronunciation info
- if the entry doesn't exist, then the task will be to create the entry with the pronunciation info
Surely the workload is more in the second case. In any event, there are many instances of not all lemmas of a language not having IPA, including Sanskrit and Hindi
- because as I said in the first discussion:
[the process of] entry creation and [the process of the] deployment of a pronunciation module even with manual intervention do not need necessarily have to be simultaneous [processes] especially since entry creation is a higher priority even if the pronunciation module is not on every applicable entry.- Entry creation (that is done properly) even without the pronunciation info is useful because it demonstrates that the term exists and adds it to the Wiktionary database. When a user is confident about the pronunciation a term, it can always be added at a later time.
- However, since Inqilābī is respectable contributor, I would be hesitant to proceed with
increasing the coverage for Old & Middle Bengaliwithout Inqilābī's input. Kutchkutch (talk) 08:31, 27 March 2022 (UTC)
Unacceptable Usernames[edit]
These should be blocked permanently- this is inherent in the account itself, rather than a temporary behavioral problem. Also, the general practice on Wiktionary is to permanently block spammers, though an argument could be made that some user-page spammers don't know it's against the rules.
Search-Engine Optimization spam consisting of links intended for the search engines to see, but camouflaged in innocuous-looking text, are an abomination. They should be deleted and the account blocked permanently (the perpetrators deserve far worse- I'm sure @Equinox would be happy to give you the full details...). Thanks! Chuck Entz (talk) 15:00, 28 September 2022 (UTC)
- @Chuck Entz: Thanks for the advice and reminder that unacceptable usernames should be blocked permanently and any search-engine optimization spam should be deleted. Kutchkutch (talk) 17:54, 28 September 2022 (UTC)
Gujarati[edit]
How much do you know about the Gujarati language? This entry needs expansion. Apisite (talk) 03:16, 29 October 2022 (UTC)
- @Apisite: Hello Apisite! Thanks for the message. My knowledge of Gujarati is somewhere between basic and intermediate. I've expanded the entry for વીર (vīr). Please have a look at it. Unfortunately, the most prolific Gujarati contributor to date User:DerekWinters / User:Smettems appears to have retired. Kutchkutch (talk) 06:13, 29 October 2022 (UTC)
- Couldn't the situation you talked about be some fair opportunity to improve your understanding of the Gujarati language? --Apisite (talk) 06:20, 29 October 2022 (UTC)
- Also, Master po00 (talk • contribs) seemed to have little to no idea what he or she was doing. --Apisite (talk) 06:22, 29 October 2022 (UTC)
- @Apisite: Yes, the situation does suggest that this is a fair opportunity to both improve the coverage of Gujarati and my own understanding of the language. According to the quantitative statistics at Wikipedia and User:AryamanA/stats, it's the fifth most spoken Indo-Aryan language with 60 million speakers after
Hindi-Urdu (c. 329 million), Bengali (242 million), Punjabi (about 120 million) and Marathi (112 million), and all of these languages (except Hindi) have less than 6,000 lemmas at Wiktionary. However, there are relatively very few resources available to learn these languages for non-native speakers (let alone the minority languages such as CAT:Parkari Koli language), which a significant impediment to expanding their coverage. In addition, my editing has been slower and more infrequent recently. Kutchkutch (talk) 07:07, 29 October 2022 (UTC)
- @Apisite: Yes, the situation does suggest that this is a fair opportunity to both improve the coverage of Gujarati and my own understanding of the language. According to the quantitative statistics at Wikipedia and User:AryamanA/stats, it's the fifth most spoken Indo-Aryan language with 60 million speakers after
IP address[edit]
Hi @Kutchkutch - I hope you're well. I believe you're an admin on Wiktionary. There's an IP address who contributes to Urdu lemmas, who doesn't add the wiki links to the definition like at عمومی and مدعی. Would there be any way to contact this user or what would be the appropriate way to fix this? نعم البدل (talk) 00:42, 18 November 2022 (UTC)
- Hello @نعم البدل,
- Sorry about the delayed response, and thanks for letting me know. Although the omission of wikilinks is inconsistent with the expected entry style, this alone would not justify any administrative actions. There is a talk page for this IP address at
- Although we could try leaving a message there, IP addresses are unlikely to read or respond to any messages. The situation could be handled by:
- asking a bot operator for an automated solution (see WT:Bots) or
- manually monitoring recent changes related to Urdu and taking any necessary actions one at a time. See Recent changes for Urdu.
- Kutchkutch (talk) 01:20, 20 November 2022 (UTC)
How do you add a language code?[edit]
There isnt one for Old Telugu, Old Malayalam or Proto South Dravidian AleksiB 1945 (talk) 08:02, 19 May 2023 (UTC)
- @AleksiB 1945: See Wiktionary:Languages. Language codes are added by editing the data modules of Module:languages, which can only be edited by template editors & administrators. Since you are not a template editor or administrator, you would have to start a discussion justifying the need for the desired language codes, wait for an outcome of that discussion and then ask template editors & administrators to make the agreed upon changes. See the link below. Kutchkutch (talk) 23:14, 19 May 2023 (UTC)
- Discussion moved to Category_talk:Proto-Dravidian_language#Old_Telugu_&_Old_Malayalam.
Transliteration for Dr langs[edit]
I had added translit for Gondi (te script), Kuvi (oriya script) and others but it isnt working, what else should be done? and languages like Gondi are written with multiple scripts and there is a module which shows the variants (same as the one used for Azeri but cant find the module page, its used in एनी) it shows Devanagari and Telugu but not the other scripts, what should be done? — This unsigned comment was added by AleksiB 1945 (talk • contribs) at 12:53, 26 May 2023 (UTC).
- @AleksiB 1945 Thanks for trying to improve the coverage of these Dravidian languages. For a transliteration module to be in effect, it has be added to the language's properties in the appropriate data submodule of Module:languages by a template editor or administrator. For languages with multiple scripts the preferred naming scheme is
Module:LANG-SCRIPT-translitsuch as Module:gon-Telu-translit for Gondi in the Telugu script.
- I would recommend adding language-specific testcases and customisations to these transliteration modules if they are known. For Telugu-script languages, it might have been easier to use MOD:te-translit if there are no language-specific testcases or customisations. However, now that these transliteration modules have been created they might as well remain. Also, the only difference for the transliteration modules for the Oriya-script languages appears to be
ainstead ofô. Some languages may write the glottal stop withʔor’. An issue with the Oriya script is that there may be no straightforward way to distinguish the short & long forms ofa,oande. In a wordlist for Kui in the Oriya script, ଅ instead of ଓ is used for /o/. Thus, soḍu derived from Proto-Dravidian *col is written as ସଡୁ instead of ସୈଡୁ. In a wordlist for Kuvi in the Oriya script, ଏଏ is used forēand ଓଓ is used forō. Thus, ēyu is written as ଏଏଯୁ instead of the current spelling used at ଏଯୁ. In addition,ais written as ଆ, andāis written as ଆଆ. A wordlist for Koya in the Oriya script follows the same transliteration as Oriya since there does not appear to be distinction between the short & long forms ofoande. The Gunjala Gondi script has no shortoande, and Masaram Gondi has no longoande.
- Usually alternate scripts are given on the headword line. Since there are five scripts for Gondi, using a template may be better. The Azeri template that you are referring to is T:az-variant. There is also T:ug-variant. Template:fa-regional exists as well, but using it as a guide it may be less helpful. I can try to look into Template:gon-variant, but I don't consider myself proficient at template editing so don't expect anything soon. Kutchkutch (talk) 06:06, 27 May 2023 (UTC)
- Thanks for adding them and its better to have different pages as many of the languages have phonemes which cant be represented by the Telugu, Odia and Devanagari scripts mainly the short and long a, e, o with Odia and Devanagari scripts as you mentioned. Its also hard to find their orthographies or words in their scripts, how did you find out ē is written as ଏଏ and so on? AleksiB 1945 (talk) 11:49, 29 May 2023 (UTC)
- Now that the modules were made, why arent you adding them to the Module:languages page? AleksiB 1945 (talk) 17:11, 31 May 2023 (UTC)
- @AleksiB 1945: Module:languages is a critical module for all of English Wiktionary, so it is important to take the time to ensure that edits to Module:languages are done carefully. I intend to add these transliteration modules to Module:languages as soon as possible.
- ē written as ଏଏ, etc. is used in certain publications by the Government of Odisha and in the Kuvi-Oriya-English Dictionary by the Central Institute of Indian Languages. Since using this convention may not be universal even within the same document, perhaps it would be better to use head parameter
|head=in the{{head}}template for ଅଅ, ଆଆ, ଏଏ, ଓଓ, etc. So for ଏଯୁ the page title could remain the same and{{head|kxv|noun|head=ଏଏଯୁ|tr=ēyu}}could display ଏଏଯୁ (ēyu) on the headword line. Kutchkutch (talk) 06:04, 1 June 2023 (UTC)
- ē written as ଏଏ, etc. is used in certain publications by the Government of Odisha and in the Kuvi-Oriya-English Dictionary by the Central Institute of Indian Languages. Since using this convention may not be universal even within the same document, perhaps it would be better to use head parameter
@Kutchkutch hey can you add kn-translit for malayalam and tamil to transliterate Byari and Sankethi AleksiB 1945 (talk) 10:22, 22 December 2023 (UTC)
@Kutchkutch, G0d0_2019: Should Odishan Dr langugage words with v be spelt with ଵ (vô) or ୱ (wô)? w:Odia_script says ୱ is the common letter and ଵ has not gained full acceptance, while wikt's only word with them is ଵିଷ୍ଣୁ (viṣṇu). AleksiB 1945 (talk) 13:32, 8 March 2024 (UTC)
- @AleksiB 1945 In my opinion, it depends on whether the Dr languages in question have (v) as a proper consonant (in which case it shall be ଵ) ; or is it like a semiconsonant/diphthong (w) (if so it should be ୱ).
- (In the Odia language, both ଵ and ୱ were meant to represent "w" the semiconsonant and some Sandhis where diphthongs become this approximant w). But the way they are used today is that ଵ is used to represent foreign words with "v", which doesn't exist natively in odia; and ୱ for "w" which is native. In fact, ଵିଷ୍ଣୁ (viṣṇu) is a non-native word, the native is actually ବିଷ୍ଣୁ (biṣṇu). To explain the diphthong part, take for example the Odia word swāgôtô (welcome) comes from su (good) + āgôtô (arrival) or suāgôtô, and subtly it is also pronounced so.
- It is also possible that these Dr languages have both the "w" and the "v", unlike Odia. In that case, we can still use the same logic, ଵ for the consonant; ୱ for the semi. Would we need a native speaker for this? or do we have enough linguistic works to come to a decision? Is the difference between "v" and "w" even that prominent in these languages?
- Alternatively, we could forget all of the above and look at some orthography and see what they are doing. The limitation with this is that (as I understand) written versions of these tribal languages have usually been authored by outsiders, and for the native speakers these are predominantly spoken languages. G0d0 2019 (talk) 18:53, 12 March 2024 (UTC)
July 2023 - October 2023[edit]
Can a bot add lemmas from dictionaries and ml wikt? There seems to be User:SinonquoiBot adding Burusho lemmas and User:Bot-Jagwar adding en wikt Malayalam lemmas to Malagasy wikt AleksiB 1945 (talk) 16:09, 17 July 2023 (UTC)
Now that there are pages on Dravidian sub branches apart from Central and North (there arent much resources on them) and that most agree on naming Tamil-Tulu and South and Telugu-Kui as South-Central why arent the branches added? AleksiB 1945 (talk) 12:13, 28 July 2023 (UTC)
@Kutchkutch, Hey could you list Malayalamoid languages under Malayalam, Tamiloid languages under Tamil and Malayalam under Old Tamil? also having the code for proto South Dravidian (Tamil-Tulu), proto macro South Dravidian (Tamil-Telugu) and dv-IPA? AleksiB 1945 (talk) 07:28, 17 October 2023 (UTC)
- @AleksiB 1945: I am really sorry about the late reply. I am not familiar enough with bots to sufficiently answer the first question, so if an answer to that is needed, you could try asking elsewhere. My guess is that it is possible, but I have no idea how to do so. Also, see the policy about bots at Wiktionary:Bots. For the second question if you are referring to User_talk:AleksiB_1945#Proto-Dravidian_entries, It may be wise to see if Pulimaiyi has time for this since he said
I will be adding the codesat User_talk:AleksiB_1945#Proto-Dravidian_entries. However, since a lot of time has passed since that discussion, I may try doing something about that. Kutchkutch (talk) 01:33, 20 October 2023 (UTC)- @Kutchkutch yes, Pulimaiyi has been inactive for over a month, also can you Malayalamoid languages under Malayalam, Tamiloid languages under Tamil and Malayalam under Old Tamil, now in pages like നങ്കൂരം (naṅkūraṁ) etymology cant be added AleksiB 1945 (talk) 14:43, 26 October 2023 (UTC)
Saraiki – Old Punjabi[edit]
@Kutchkutch Hi, could you please list Old Punjabi as an ancestor of Saraiki, and while you're there could you also set Module:pa-Arab-translit as the transliteration module for Urdu? نعم البدل (talk) 21:05, 25 August 2023 (UTC)
- @نعم البدل: I am really sorry about the late reply. As you probably already know, MOD:ur-translit is now being used for the translit module for Urdu (see diff by Benwing2 and diff by User:Fenakhay). In this diff by User:Theknightwho, the ancestor of the CAT:Lahnda language was changed to CAT:Old Punjabi language, which automatically made CAT:Saraiki language a descendant of CAT:Old Punjabi language. Although I have never opposed making Old Punjabi as an ancestor of Saraiki, please see what User:Taimoorahmed11 said at User_talk:IMPNFHU#Reverting_and_Removal_of_inc-opa
I'm not sure whether making Old Punjabi an ancestor of Saraiki is wise - from what I know, it's a pretty controversial issue, and I'm not a Saraiki speaker to even be able to give a solid opinion on this.
- Shouldn't CAT:Lahnda language be deprecated like CAT:Western Panjabi language? Kutchkutch (talk) 01:19, 20 October 2023 (UTC)
- @Kutchkutch: No worries. Unless or until there's evidence of Old Saraiki that is in some way different to Old Punjabi, I don't see why it would be controversial to nominate Saraiki as a direct descendant of Old Punjabi. Also, yes – Lahnda should be a deprecated language, I don't even see the need for it. Existing pieces of 'Lahnda' should be integrated with Punjabi instead. نعم البدل (talk) 11:24, 20 October 2023 (UTC)
- @نعم البدل: Is CAT:Punjabi language really the apt replacement for CAT:Lahnda language? I always assumed that CAT:Saraiki language would be the replacement for CAT:Lahnda language since it is the most spoken Lahnda language and the one with the most coverage at Wiktionary. Neither CAT:Lahnda language nor CAT:Punjabi language are treated as macrolanguages at Wiktionary:Language treatment. According to Wikipedia, Lahnda collectively refers to Saraiki, Hindko, Pahari-Pothwari and Khetrani. The Wiktionary language family that corresponds to this grouping is CAT:Punjabi-Lahnda languages. So, when listing cognates or creating descendants trees, would CAT:Lahnda language be replaced be a single language such as CAT:Punjabi language / CAT:Saraiki language or would it be replaced by CAT:Punjabi-Lahnda languages similar to CAT:Hindustani languages? Kutchkutch (talk) 02:31, 23 October 2023 (UTC)
- @Kutchkutch:
I always assumed that CAT:Saraiki language would be the replacement for CAT:Lahnda language
– Yeah Saraiki sorry. My point was merely that CAT:Lahnda language should be archived.So, when listing cognates or creating descendants trees
– most of the descendants tree are sourced from Turner's dictionary, which also lists Pothwari as a separate dialect right? I've always taken Lahnda to be Saraiki, in fact most of the 'Lahnda lemmas' under descendant trees are more often than not, spelled incorrectly and while correcting them I've changed them to Saraiki previously. @Notevenkidding might have something to say on the matter, as a native Saraiki speaker.- Hindko also needs to be sorted out – currently we have two language codes for it, a northern dialect and a southern dialect I believe, even though the language itself is not too different from Standard Punjabi. نعم البدل (talk) 16:20, 23 October 2023 (UTC)
- I guess it depends on whether we want to have a 'Lahnda'-like group as an ancestor of the 'Western' dialects, or would it suffice to merely list all the dialects as descendants of Old Punjabi? In any case, my opinion is that 'Lahnda' is Saraiki. نعم البدل (talk) 16:24, 23 October 2023 (UTC)
- @Kutchkutch:
- @نعم البدل: Is CAT:Punjabi language really the apt replacement for CAT:Lahnda language? I always assumed that CAT:Saraiki language would be the replacement for CAT:Lahnda language since it is the most spoken Lahnda language and the one with the most coverage at Wiktionary. Neither CAT:Lahnda language nor CAT:Punjabi language are treated as macrolanguages at Wiktionary:Language treatment. According to Wikipedia, Lahnda collectively refers to Saraiki, Hindko, Pahari-Pothwari and Khetrani. The Wiktionary language family that corresponds to this grouping is CAT:Punjabi-Lahnda languages. So, when listing cognates or creating descendants trees, would CAT:Lahnda language be replaced be a single language such as CAT:Punjabi language / CAT:Saraiki language or would it be replaced by CAT:Punjabi-Lahnda languages similar to CAT:Hindustani languages? Kutchkutch (talk) 02:31, 23 October 2023 (UTC)
- @نعم البدل: Sorry about the late response.
most of the descendants tree are sourced from Turner's dictionary, which also lists Pothwari as a separate dialect right?
- – Yes, most descendants trees that pertain to inheritance rather than borrowing are sourced from Turner's dictionary. Pothwari is listed as a dialect of the 'Lahnda language' as
poṭh. Poṭhwārī dialect of Lahndāat:
most of the 'Lahnda lemmas' under descendant trees are more often than not, spelled incorrectly
- – The reason why this may be the case is that those spellings were obtained by converting the romanisation in Turner's dictionary to the Perso-Arabic script.
Hindko also needs to be sorted out – currently we have two language codes for it, a northern dialect and a southern dialect
- – Yes, there are two language codes for Hindko. However, in the absence of more information about Hindko other than what is in
A Descriptive Grammar of Hindko, Panjabi, and Saraikiand the somewhat confusing description on Wikipedia, it is unclear to me whether two separate language codes are really needed or if they can be merged as a single language code.
- The description on Wikipedia:
- The central dialect group comprises Kohati ... and the three closely related dialects of Attock District, Punjab: Chacchi (spoken in Attock), Ghebi (spoken to the south in Pindi Gheb Tehsil) and Awankari (spoken in Talagang Tehsil, now part of Chakwal District)
- Shackle, however, sees most of them as closely related to the urban variety of Peshawar City
- The whole dialect continuum of Hindko is partitioned by Ethnologue into two languages: Northern Hindko (ISO 639-3 code: hno) for the dialects of Hazara, and Southern Hindko (ISO 639-3: hnd) for the remaining varieties.
- The description on Wikipedia:
- Although the language described in Hardev Bahri's books Lahndi Phonology and Lahndi Phonetics is called Lahndi, it is actually the Awankari dialect of Hindko. I see that you have had a discussion about Hindko at User_talk:عُثمان#Hindko_Dictionary. Although books mentioned there may be of use for Wiktionary, obtaining Pakistani books from India may be difficult if not impossible.
it depends on whether we want to have a 'Lahnda'-like group as an ancestor of the 'Western' dialects,, or would it suffice to merely list all the dialects as descendants of Old Punjabi?
- – Since there is not much coverage for other Lahnda languages other than Saraiki, I just wanted to see what your stance on this matter if it arises in the future. I am also of the opinion that
'Lahnda' is Saraiki
when there is no further information about the otherLahnda languages. Kutchkutch (talk) 10:57, 12 November 2023 (UTC)
Transliteration module for Kru[edit]
Hi kutchkutch, I see that you have helped include transliteration modules for Gondi and Kui. I need your help in establishing a transliteration module for the Kurukh language in Devanagari script. I have made some changes to this Module:kru-Deva-translit, but I am new to how transliteration modules work. I have tried to make the module based on this Kurux Phonetics and Transliteration by the CIIL, see pages 26-30. The only thing I have added is the ' for glottal stops. Can you please check the module and see if it is possible to structure it according to the standard? If it is good to go, can you please include it? Or will I have to stick to manual transliteration? G0d0 2019 (talk) 19:35, 27 November 2023 (UTC)
- @G0d0 2019: Sorry for the delayed response, and thanks for noticing my edits to the modules related to Gondi and Kui. For now I have put MOD:hi-translit as the transliteration module for Kurukh in Devanagari script as a fallback. More testcases are needed at MOD:kru-Deva-translit to determine whether having a Kurukh-specific transliteration module that is separate from MOD:hi-translit is needed. It seems Kurukh has schwa-dropping like Hindi, which I do not know how to implement. Kutchkutch (talk) 21:29, 5 January 2024 (UTC)
- The only differences are the apostrophe for glottal stop and – for long e/o like ए–न for ēn as used in these Kurux websites [21] [22] AleksiB 1945 (talk) 10:19, 7 January 2024 (UTC)
- The module is failing with ख़, which should be x, instead returns kh. Also, all the 5th nasal consonants are being returned as ṃ, instead of ṅ,ñ,ṇ,n. This seems like a dead end. But, I thankyou both for your efforts. G0d0 2019 (talk) 19:12, 12 March 2024 (UTC)
- कुंड़ुख़ (kũṛux), कींदा (kīndā), एँड़ (ẽṛ), खंजपा (khañjpā) it works? AleksiB 1945 (talk) 12:48, 13 March 2024 (UTC)
- The module is failing with ख़, which should be x, instead returns kh. Also, all the 5th nasal consonants are being returned as ṃ, instead of ṅ,ñ,ṇ,n. This seems like a dead end. But, I thankyou both for your efforts. G0d0 2019 (talk) 19:12, 12 March 2024 (UTC)
- The only differences are the apostrophe for glottal stop and – for long e/o like ए–न for ēn as used in these Kurux websites [21] [22] AleksiB 1945 (talk) 10:19, 7 January 2024 (UTC)
Your edit to Module:number list/data/ur left this entry with a module error. You need to fix either the module or the entry. My best guess is that the {{number box}} template should be removed from the entry, but what do I know? Chuck Entz (talk) 20:02, 5 January 2024 (UTC)
- @Chuck Entz: Thanks for letting me know. I forgot that this data module can cause module errors, and I should have checked CAT:E afterwards. The error was caused by an invisible character in the data module. Kutchkutch (talk) 21:29, 5 January 2024 (UTC)
Kolami/kolava swadesh list devnagari text transliteration issue[edit]
Hello sir theirs a problem in wiki page kolami swadesh list, while telugu transliteration is available, theirs no devanaagari transliteration, available, so sir please can you add it for kolami/kolava swadesh list in original sanskrit word structure style so i can use the words like ñ,
ङ्, ञ्, पान(pāna), पान्(pān).thank you, hope you accept the request. Ganesudu (talk) 09:42, 7 February 2024 (UTC)